
Francesco Nicoli – junior professor of political economy
« L'Europe se fera dans les crises et elle sera la somme des solutions apportées à ces crises »—Jean Monnet
Information Overflow and the quality of the public debate

Post- Brexit, there has been a growing discussion on how the internet has deteriorated the quality of the public debate, fuelling a run-to-the-bottom between publishers to provide low-quality information aimed to maximise readerships through click-baits strategies. The misconceptions concerning benefits & costs of European integration not only played a fundamental role in the Brexit vote, but continue to fuel populistic resentment all over the Continent; poor information or outright lies sold as “news” are shifting the public discussion in many mature democracies, strengthening the hand of ruthless populistic politicians.
In this series of posts I will attempt to dig further into the dynamic relationship between democracy and information. This first post is a simple attempt to formalize & model the dynamics described above: while some more information increases the quality of the public debate, too much free information ends up deteriorating it. You can read the second post, dedicated to the relationship between populism, media and expertise, here.
The key insight of my analysis is that, as the monetary costs of accessing information decrease, eventually reaching zero, other “immaterial” costs emerge, especially the “time” cost of sorting “true” information among a potentially limitdless supply of information. This is particularly true in a world where an infinity of agents can produce information and news through the internet (both “true” information and “bad” information). However, the quality of the public debate requires that citizens discuss on the basis of “true” information; a public discussion based on inaccurate, misleading or simply false information would drammatically decrease the quality of the public debate, thus undermining democracy. The problem is that citizens (“information seekers”) will attempt to maximise the amount of information they get, but the community as a whole wouldn’t necessarily profit from it.
To model it, let’s first assume that a reverse relationship exists between C (the monetary cost of accessing information) and Q, the total information (produced and consumed).This way, for now, we can simply ignore C: we know that, automatically, when Q increases C decreases. I will come back on this on the second part of this post.
Let’s also assume that a certain share of the total information Q available is “false”, wrong, or misleading information. Let’s call α the parameter of total information Q that, in fact, identifies the share of “true” information. Conversely, 1-α represents the share of “wrong” information.Similarly, let’s call p the agents’ “prior” believes about how reality is or should be. As agents obtain satisfaction from discovering that the reality is conformed to their prior believes, the share p of information also enters in the gross benefit function of the information seekers. I will come back to this issue later.
Let’s assume then that a third parameter, β, represents the value, for a citizen, of one unit of information, either “objective” or conformed to its prior believes. The “gross benefits” expected by being active on the information market as information seekers is therefore
(1)
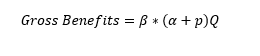
Where α and p are both comprised between 0 and 1. Conveniently, the societal optimum and the individual optima are related, being the quality of the public debate (the societal optimum) a function f of all individal B*a (the more the public is well-informed, the better quality is the public debate). However, social optimum and individual optimum are not equal, as the society as a whole profits only from the “alfas” (the share of true information) but not from the p (the share of information conformed to agents’ priors). The former helps public discussion, the latter, at best, does not harm it.
Now, a decrease in the monetary costs of information increases the availability of total information: remember that as monetary costs decrease, Q increases (see later for details). However, let’s assume there is a second component of “costs” for “good” information: a time-cost that information-seeker agents incur in order to discern “good” information from “bad” information. This cost grows exponentially with the amount of total information (both true and wrong) available on the market, as information must be compared in order to discern good and bad news. We can thus define the temporal costs of accessing free information as.
(2)
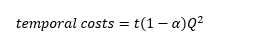
There t is a parameter identifying the amount of time needed to process each unit of information, (1-α) identifies the share of “wrong” information to be detected by comparison and Q^2 is the quadratic of total information available, which identifies the costs of comparing information. As explained later, p (our priors) do not enter in this part of the equation, because it rather used as a strategy to reduce Q. By composing (1) and (2) we obtain the net benefits of processing free information:
(3)
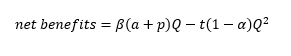
Which in fact describes an inverse parabolic curve in the Cartesian plane. For low very amount of Q (and therefore high monetary costs, C), the total costs are low but so are the expected benefits; for very large amounts of Q (implying very low C), the costs of comparing all information grow exponentially outpacing the benefits. It follows that, ideally, there is optimal Q (OQ) which maximises the benefits.
The quantity of Q that maximises the individual payoff from information is not “infinite”, and therefore the ideal cost of information, for the citizen, is not “zero”. In fact, if that were the case, the payoff of searching information would be very limited, because, despite the zero monetary costs of getting news, the time-costs of comparing them to discern the true from the false news tend to increase towards infinite. In fact, paying a price can be considered as a mean to limit the amount of information available to that part with higher alfas – meaning, higher probability of being correct. We would expect, therefore, that citizens are willing to “reduce” the pool of information from which sort “true” and “false” news in order to maximise their benefits. Intuitively, the first mechanism that ensures such an outcome (limiting the pool of information) simultanously ensuring limited time-costs would be to pay for high-end journalism. Conveniently, such a behaviour is also the optimum for the society as a whole, as the quality of the public debate B (which is a function of all individual betas) is maximised when individuals maximise their alfa* betas.
Unfortunately, this is seldom what we observe today.
The trend is rather going in the opposite direction. A possible explanation is that the majority of information-seekers have a positive bias for “free stuff”. Meaning, if an alternative solution, other than to pay for information, is available to reduce the pool of information one has to discern, then the the agent will use that other strategy instead of paying. Many reasons may explain such a behaviour: young people, the majority of internet users, have limited amount of money to spare; paying is already factored in as we pay for an internet connection; money is perceived as better-used elsewhere (meaning information is a second-tier good); etc. What we are really interested in, however, is the kind of alternative pool reduction strategy agents set up. This is key, because in a situation like today’s “free” internet, when a large amount of information is incorrect or misleading, the temporal costs of detecting free information by looking upon all the media outlet available can be very high.
In order to introduce such a pre-selection mechanism, a further mathematical step is needed. let’s assume that the “consumed” Q is a share of the total available information (TQ) in the market.
Let’s define c as a price index, and p a “priors” index, the latter identifying how restrictive are our believes. Both vary between 0 and 1: very low c indicates low prices, while very low p indicates non-restrictive priors. As noted several times before, Q it is negatively correlated to c, and it is, to some extent, negatively correlated with our priors p. Equation 4 explains this relation:
(4)
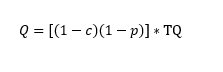
When c is low, (1-c) is very large, and therefore p must be large for (1-p) to being small and thus reduce the share of TQ accessed. Now, in order to maximise the net benefits of being an active member of te information market, the quantity of information consumed must be the optimal quantity. It follows that, when C is very large, (1-c) is very small, then the “consumed” quantity of information is close to the optimum only when the agents tend to be indifferent among different sources (p is small); similarly, when C is very small and 1-c becomes larger, very strong priors are needed in order to reduce the consumption of information, which otherwise is too high.
Of course, we always have “priors”. But when TQ is very large, and if we have negative bias towards encurring monetary costs (C), then the importance of our “priors” grows exponentially because they constitute the only other mean to non-randomly reduce Q. Agents limit their information pool according with their prior understanding of which sources of information are reliable, in order to minimize the size of (1-α) by means of pre-selection. It’s important to notice that individuals cannot really maximise their net benefits function unless they are willing to incur in a monetary loss, because an increase in Q implies, by construction, a decrease in C (the monetary costs of information). If C decreases, Q increases, but increasing Q, T (the temporal cost of information) increases as well. The only individually optimal outcome, at that stage, is to limit Q by a “tool” which is not C but it’s the individual own “prior” concerning which information is good. As a result, individuals do not maximize the share of objectively “true” information they seek, but maximise instead the amount of information that confirms their priors.From the individual perspective, this does not constitute a major issue, because both p (the share of of information conformed to the priors) and a (the share of objective information) enter into the benefit function.However, from a societal point of view, only a is taken into account.
The aggregate results, once iterated over time, can be catastrophic. When information retains a monetary costs that agents are willing to encur, the competition dynamics among information providers leads to ever-better quality: agents are willing to allocate their money to those providing better information. But if information is toally free and a negative bias for monetary costs exists, the loop goes in the opposite direction: information providers compete to maximise their adherence to the priors of the potential readership. As a result, a new market equilibrium with disruptive features emerges. In fact, information looses much of its informative power and becomes unable to strengthen the quality of the public debate. On the one hand, agents look for confirmation of their prior believes (becoming, trough social media, producers of information themselves) instead of seekers of an objective reality. On the other hand, this “priors fulfillment” is precisely what the market is up for offering, in a race-to-the bottom which ends up transforming the information market into a “fulfilling priors” market.
(many thanks to Rodolfo Signorino, Roberto Iacono & Pietro Perazzi for their suggestions and patience!)

Pingback: Populism, the Rejection of Expertise, & the Demise of Democracy | ------ ABOUT CRISES ------ Francesco Nicoli's ideas den
Pingback: Populism as a Rejection of Specialisation | Nicoli